
记一次线上服务异常终止问题查询
2021-07-30 02:54:45 晓掌柜 版权声明:本文为站长原创文章,转载请写明出处
一、背景
最近,随着业务复杂度增加,服务节点又增加了一个。本地开发完成并调试后,在测试环境上能够正常运行。但是部署到线上
服务器就出现问题了:
① 服务部署上后马上被终止
② 服务运行一小段时间后被终止
时间紧迫,我这边从各个角度进行了追踪查询,终于在超出约定更新时间30+min后查到问题所在并得到解决。下面就简单记录一下
整一个过程,留一个脚印...
二、事件经过
2.1、事件起因
线上服务节点增加:业务需要我们开辟了一个新的消费者,整一个的代码及业务逻辑都已经完善,并且在测试服务器上运行OK,
就差部署到线上了。
2.2、问题描述
我们有4个生产者和2个消费者,这里就简单表述为:生产者1、生产者2、生产者3、生产者4、消费者1、消费者2。
因为生产者1和生产者2是没有业务变更的,按照正常的上线步骤:
① 把消费者1、消费者2、生产者3、生产者4停掉
② 上传并启动生产者3、生产者4
③ 上传并启动消费者1
④ 上传并启动消费者2 (这里生产者3服务被终止)
三、问题排查
3.1、线上日志查询
处理问题,第一步肯定是要进行日志查询的。这边从线上拉取日志发现:
① 生产者3正常启动
② 突然服务被终止、无异常、不涉及业务逻辑处理
3.2、nacos服务排查
后面有想,是不是说nacos服务注册发生了问题。于是在每次服务启动时就排查一下服务注册,结果:
① 每次服务启动后,nacos都能正常的被发现注册
② 出问题后服务编程不健康实例,然后消失 (这不废话吗,人家都停止了)
3.3、服务冲突猜想
到这一步了,就想着会不会是服务启动后冲突了?于是乎做了一次全线的服务重启!诶,好像可以哦,所有服务都能正常启动,
没跑了就是服务冲突了。
但是好景不长,在做流程测试时还是出现了意外:服务又被终止了,还是生产者3 !
3.4、服务器排查
在测试环境下是OK的,部署到线上出问题!而且经过上述的排查之后,我又把问题锁定在了服务器环境上!
① 首先,服务器配置是没有变动的
② 再次增加了节点后出问题,不增加节点还是OK的
③ 真相只有一个:服务器的相关配置无法满足服务节点的增加!
直接查节点在服务器上被kill的日志信息,在服务器上直接执行以下命令:
dmesg | egrep -i -B100 'killed process'
示例图如下:
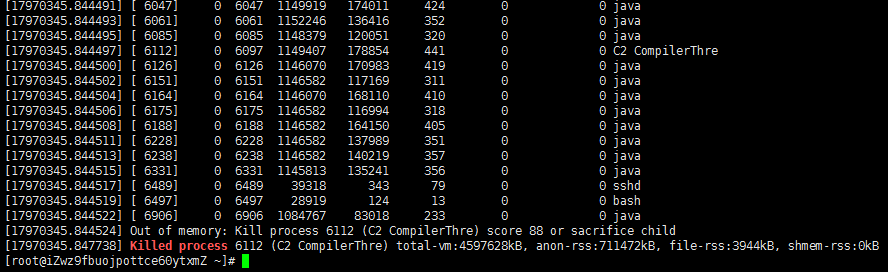
我们直接看最后一行:
Killed process 6112 (C2 CompilerThre) total-vm:4597628kB, anon-rss:711472kB, file-rss:3944kB, shmem-rss:0kB
上述信息传递的信息:
① 6112的服务进程被终止
② 服务进程占用内存为:4597628kB
③ 服务进程中为RAM分配的内存为:711472kB
④ 被映射到文件中的内存为:3944kB
⑤ OOM导致了服务被终止
PS: RSS为当前的内存占用,RSS = file-rss + anno-rss
同时当OOM出现时,系统会自动停掉内存消耗最高的那个进程,我们的生产者3内存消耗最高,就躺枪了...
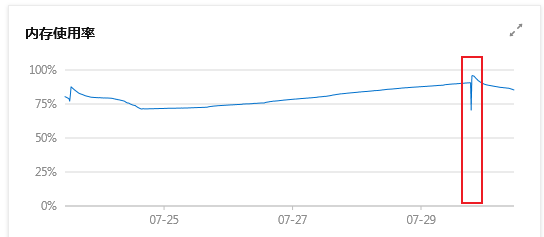
3.5、云服务器监控佐证
登录云服务器,打开性能监控发现,在服务瞬间内存被打满了:
四、问题解决
① 代码优化
② 在部署时等待线上服务稳定后在部署后一个服务
③ 多使用free -m监控下内存情况
④ 多实用top命令监控系统状态
PS:后续会退出,服务器性能监控方面的文章,敬请期待。
更多精彩,请持续关注:guangmuhua.com